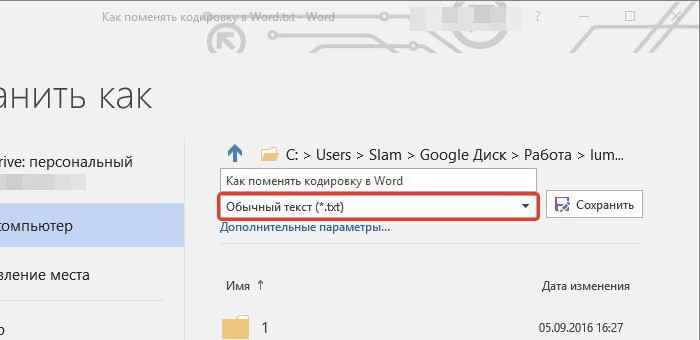
קידוד Unicode: תקן קידוד תווים
כל משתמש אינטרנט בניסיונותלהגדיר אחד או אחר של הפונקציות שלה לפחות פעם אחת לראות על המסך כתוב באותיות לטיניות המילה "Unicode". מה זה, תלמד על ידי קריאת מאמר זה.

הגדרה
קידוד "Unicode" הוא תקן קידודתווים. זה הוצע על ידי עמותת Unicode בע"מ בשנת 1991. התקן נועד לשלב סוגים רבים ככל האפשר של סמלים במסמך אחד. הדף שנוצר על בסיס שלו יכול להכיל אותיות הירוגליפים משפות שונות (מרוסית לקוריאנית) וסימנים מתמטיים. כל התווים בקידוד זה מוצגים ללא בעיות.
סיבות ליצירה
פעם, זמן רב לפני הופעתה של מערכת מאוחדת"Unicode", הקידוד נבחר על פי העדפותיו של מחבר המסמך. מסיבה זו, לעתים קרובות כדי לקרוא מסמך אחד, היית צריך להשתמש בטבלאות שונות. לפעמים זה היה צריך להיעשות כמה פעמים, אשר מסובך באופן משמעותי את חייו של משתמש רגיל. כאמור, הפתרון לבעיה זו בשנת 1991 הוצע על ידי עמותת Unicode Inc, אשר הציע סוג חדש של קידוד אופי. הוא נקרא לשלב אמות מידה מיושנות מבחינה מוסרית ומגוונת. "Unicode" - קידוד, אשר מותר להשיג את הבלתי מתקבל על הדעת באותו זמן: כדי ליצור כלי התומך במספר עצום של תווים. התוצאה עלתה על ציפיות רבות - מסמכים הופיעו בו זמנית, הן באנגלית והן בשפה הרוסית, ביטויים לטיניים ומתמטיים.
אבל היצירה של קידוד יחיד קדמהאת הצורך לפתור מספר בעיות שעלו בשל מגוון רחב של סטנדרטים שכבר היה קיים באותו זמן. הנפוצים ביותר הם:
- כתבי elfic, או "karkozyabry";
- ערכת תווים מוגבלת;
- את הבעיה של קידוד המרה;
- שכפול גופנים.

סטייה היסטורית קצרה
תארו לעצמכם כי החצר היא 80. חומרת מחשב היא לא כל כך נפוצה ויש לו צורה שונה מהיום. בעוד כל מערכת הפעלה הוא ייחודי ומעודן כל הצרכים הספציפיים של חובבי. Need for החילוף מידע מומר הכל חוזר נוסף. מנסה לקרוא מסמך שנוצר על ידי מערכת הפעלה אחרת, לעתים קרובות מציג שורה מוזרה של דמויות, והמשחק מתחיל עם הקידוד. זה לא תמיד עושה את זה מהר, ולפעמים מסמך דרושים ניתן לפתוח בתוך שישה חודשים, ואף מאוחר יותר. אנשים המרבים להחליף מידע, ליצור לעצמם טבלת המרה. ואז לעבוד עליהם חושף פרט מעניין: הצורך ליצור אותם בשני כיוונים, "מן שלי שלך" קדימה ואחורה. הפוך מכונת מחשוב היפוך בנאלי לא יכולה, זה בעמודה הימנית של המקור, ואת שמאלי - התוצאה, אך לא להיפך. אם אתה רואה את הצורך להשתמש בכל התווים המיוחדים במסמך, הם היו צריכים להתווסף הראשונה, ולאחר מכן עוד, וכדי להסביר את השותף מה שהוא צריך לעשות כדי תווים אלה אינם הופכים "ג'יבריש". ובואו לא נשכח שלכל קידוד נאלצו לפתח או ליישם גופנים משלהם, אשר הובילה ליצירת מספר עצום של כפילויות במערכת ההפעלה.
תארו לעצמכם גם כי בדף של גופנים אתהאתה תראה 10 חתיכות של פעמים ניו רומן זהה עם סימונים קטנים: עבור utf-8, UTF-16, ANSI, UCS-2. עכשיו אתה מבין כי הפיתוח של תקן אוניברסלי היה צורך דחוף?

"יוצרי אבות"
מקורותיה של היצירה של יוניקוד יש לחפש בשנת 1987כאשר ג'ו בקר מקבוצת זירוקס, יחד עם לי קולינס ומארק דייוויס מאפל, החלו במחקר על יצירה מעשית של אופי אופי אוניברסלי. באוגוסט 1988 פרסם ג'ו בקר הצעה לטיוטת מערכת קידוד בינלאומית רב-לשונית של 16 סיביות.
כמה חודשים לאחר מכן, קבוצת העבודה של יוניקודהורחב כדי לכלול את קן ויסלר ואת מייק Kernegan של RLG, גלן רייט של סאן מיקרוסיסטמס ועוד כמה מומחים, אשר אפשרה את השלמת העבודה על היווצרות ראשונית של תקן קידוד יחיד.

תיאור כללי
Unicode מבוסס על הרעיון של סמל. הגדרה זו נתפסת כתופעה מופשטת הקיימת בצורה מסוימת של כתיבה ומובנת באמצעות גרפמות ("הדיוקנאות" שלה). כל תו מוגדר ב- Unicode על-ידי קוד ייחודי השייך לבלוק מסוים של התקן. לדוגמה, Grapheme B הוא באנגלית והן ברוסית אלפבית, אבל Unicode זה מתאים 2 תווים שונים. הם מומרים אות קטנה, כלומר, כל אחד מהם מתואר על ידי מפתח מסד נתונים, קבוצה של נכסים, ואת שם מלא.
היתרונות של Unicode
מתוך קידוד בני גילם אחרים "Unicode"היה שונה מילואים עצום של סימנים "הצפנה" של סמלים. העובדה היא כי קודמיו היו 8 סיביות, כלומר, הם תמכו 28 תווים, אבל הפיתוח החדש כבר 216 תווים, אשר היה צעד ענק קדימה. זה מותר לקודד כמעט את כל האלפבית הקיים ומופץ.
עם הופעתו של "Unicode" כבר לא נחוץשימוש בטבלאות המרה: כסטנדרט אחד, זה פשוט מבטל את הצורך שלהם. כמו כן, "krakozyabry" גם נעלם לתוך שכחה - תקן אחד גרם להם בלתי אפשרי, כמו גם לבטל את הצורך ליצור גופנים כפולים.
פיתוח Unicode
כמובן, ההתקדמות לא עומדת דוממת, ומהרגעהמצגת הראשונה כבר עברה 25 שנים. עם זאת, קידוד Unicode בעקשנות שומרת על מעמדה בעולם. במובנים רבים זה הפך אפשרי בשל העובדה כי הוא הפך להיות מיושם בקלות להתפשט, להיות מוכר על ידי היזמים של תוכנה קניינית (בתשלום) וקוד פתוח.

במקרה זה, אין צורך להאמין כי היום אנחנואותו קידוד Unicode זמין כרבע לפני מאה שנה. כרגע, הגרסה שלה השתנתה ל 5.x.x, ומספר הדמויות המקודדות עלה ל 231. מן האפשרות להשתמש מלאי גדול יותר של תווים סירב עדיין לשמור על תמיכה Unicode-16 (קידודים, שם המספר המרבי היה מוגבל 216). מרגע הופעתה לגרסה 2.0.0, "Unicode-standard" הגדילה את מספר הדמויות שכללו אותה, כמעט פי 2. צמיחת ההזדמנויות נמשכה גם בשנים הבאות. לגירסה 4.0.0 היה כבר צורך להגדיל את התקן עצמו, אשר נעשה. כתוצאה מכך, יוניקוד רכשה את הצורה שבה אנו מכירים אותה כיום.

מה עוד יש ביוניקוד?
בנוסף ענק, כל הזמן לחדשמספר התווים, "Unicode" - קידוד של מידע טקסטואלי יש עוד תכונה שימושית. אנחנו מדברים על מה שנקרא נורמליזציה. במקום לגלול את סמל המסמך כולו לפי תו ולהחליף סמלים תואמים מטבלת ההתאמה, נעשה שימוש באחד האלגוריתמים הקיימים לנורמליזציה. על מה אנחנו מדברים?
במקום לבזבז משאבי מחשובמכונות לבדוק באופן קבוע את אותו סמל, אשר יכול להיות דומה ב אלפביתות שונות, משתמשת באלגוריתם מיוחד. זה מאפשר לך להוציא תווים דומים בגרף נפרד של שולחן בדיקה להתייחס אליהם כבר, ולא לבדוק שוב ושוב את כל הנתונים.
ישנם ארבעה אלגוריתמים כאלה שפותחו ויושמו. בכל אחד מהם, הטרנספורמציה מתרחשת על פי עיקרון מוגדר לחלוטין, השונה מן האחרים, ולכן לא ניתן לנקוב בשמו של אחד מהם בצורה היעילה ביותר. כל אחד מהם פותח עבור צרכים ספציפיים, יושם בהצלחה בשימוש.

התפשטות התקן
במשך 25 שנים של ההיסטוריה שלה קידוד "Unicode"כנראה קיבל את ההתפלגות הגדולה ביותר בעולם. על פי תקן זה, גם תוכניות ודפי אינטרנט מותאמים. רוחב היישום ניתן לומר על ידי העובדה יוניקוד היום משתמשת ביותר מ 60% של משאבי אינטרנט.
עכשיו אתה יודע מתי הסטנדרטי "Unicode" הופיע. מה זה, אתה גם יודע יוכלו להעריך את הערך המלא של ההמצאה שנעשו על ידי קבוצה של מומחים מ Unicode בע"מ לפני יותר מ -25 שנה.